В статье описано, как получить список уникальных значений в столбце с помощью формулы и как настроить эту формулу для различных наборов данных. Вы также узнаете, как быстро найти уникальные значения с помощью расширенного фильтра Excel и как извлечь уникальные записи с помощью Duplicate Remover.
В нескольких недавних статьях мы обсудили различные методы подсчета и поиска уникальных значений в Excel. Если у вас была возможность прочитать эти руководства, вы уже знаете, как получить этот список при помощи идентификации, фильтрации и копирования. Но это немного длинный и далеко не единственный способ извлечения уникальных значений в Excel. Вы можете сделать это намного быстрее, используя специальную формулу. И сейчас я покажу вам этот и несколько других приёмов.
Базовые формулы чтобы найти уникальные значения
Чтобы избежать путаницы, сначала давайте договоримся о том, что мы называем уникальными значениями в Excel.
Уникальные значения - это значения, которые присутствуют в списке только один раз. Например:

Чтобы получить список уникальных значений в Excel, используйте одну из следующих формул.
Формула уникальных значений массива (заполняется нажатием Ctrl + Shift + Enter):
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0; СЧЁТЕСЛИ($B$1:B1;$A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10; $A$2:$A$10)<>1); 0)); "")
В этой формуле для выявления дубликатов в столбце мы используем функцию СЧËТЕСЛИ. Подробнее о ней читайте в этой статье: СЧЕТЕСЛИ в Excel - примеры функции с одним и несколькими условиями.
Можно воспользоваться и обычной формулой (вводится нажатием Enter):
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0;ИНДЕКС(СЧЁТЕСЛИ($B$1:B1; $A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10; $A$2:$A$10)<>1);0;0); 0)); "")
Подробнее о том как выявить дубликаты в столбце, читайте в этой статье: 10 способов найти повторяющиеся значения.
В приведенных выше формулах используются следующие ссылки:
- A2: A10 – исходных перечень данных.
- B1 - верхняя ячейка уникального списка минус одна строка. В этом примере мы начинаем создавать список уникальных в B2, и поэтому мы записываем B1 в формулу (B2 - 1 строка = B1). Если ваш список начинается, скажем, с ячейки C3, измените $B$1:B1 на $C$2:C2.
Примечание. Поскольку формула ссылается на ячейку, расположенную над первой ячейкой создаваемого списка, который обычно является заголовком столбца (B1 в этом примере), то убедитесь, что ваш заголовок имеет уникальное имя, которое больше нигде в этом столбце не появляется.
Подробно работа функции ПОИСКПОЗ рассмотрена здесь: Функция ПОИСКПОЗ в Excel: полное руководство.
В этом примере мы извлекаем уникальные имена из столбца A (точнее из диапазона A2: A10), а следующий скриншот демонстрирует формулу в действии:

Вот наш порядок действий:
- Измените любую из формул в соответствии с вашим диапазоном данных.
- Введите ее в первую ячейку, с которой начнётся формирование списка (в данном примере B2).
- Если вы используете формулу массива, нажмите
Ctrl + Shift + Enter. Если вы выбрали обычную, нажмите просто клавишуEnter. - Скопируйте вниз настолько, насколько это необходимо, перетащив мышкой маркер заполнения. Поскольку обе формулы заключены в функцию ЕСЛИОШИБКА, вы можете скопировать вниз с запасом. Это не испортит ваши данные какими-либо ошибками, независимо от того, сколько уникальных значений было извлечено.
Как извлечь различные значения.
Различные значения — появляются в перечне данных хотя бы один раз. Это все уникальные и первое вхождение повторяющихся значений.
Например:

Чтобы получить их список в Excel, используйте следующие формулы.
Формула массива (требуется нажать Ctrl + Shift + Enter):
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0; СЧЁТЕСЛИ($B$1:B1; $A$2:$A$13); 0)); "")}
или можно так:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; НАИМЕНЬШИЙ(ЕСЛИ(ЕНД(ПОИСКПОЗ($A$2:$A$13;$B$1:B1;0)); СТРОКА($A$1:$A$15);"");1));"")}
Обычная формула:
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0; ИНДЕКС(СЧЁТЕСЛИ($B$1:B1; $A$2:$A$13); 0; 0); 0)); "")
Где:
- A2: A13 - это список источников.
- B1 - это ячейка над первой ячейкой отдельного списка. В этом примере отдельный список начинается с ячейки B2 (это первая ячейка, в которую вы вводите формулу), поэтому вы ссылаетесь на B1.
Более подробно о формуле ИНДЕКС ПОИСКПОЗ, читайте по ссылке: ИНДЕКС ПОИСКПОЗ как лучшая альтернатива ВПР.

Как найти уникальные значения, игнорируя пустые ячейки
Если исходный список содержит пустые ячейки, формула, которую мы только что обсудили, вернет ноль для каждой пустой строки, что может быть проблемой. Это вы и наблюдаете на скриншоте чуть выше. Чтобы исправить это, сделаем несколько небольших корректировок.
Формула массива для извлечения различных значений, исключая пустые ячейки:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0;СЧЁТЕСЛИ($C$1:C1;$A$2:$A$13&"") + ЕСЛИ($A$2:$A$13="";1;0); 0)); "")}
Аналогичным образом вы можете получить список различных значений, исключая пустые ячейки и ячейки с числами:
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0;СЧЁТЕСЛИ($D$1:D1;$A$2:$A$13&"") + ЕСЛИ(ЕТЕКСТ($A$2:$A$13)=ЛОЖЬ;1;0); 0)); "")}
Напоминаем, что в приведенных выше формулах A2: A13 – это исходный список, а B1 – ячейка прямо над первой позицией формируемого списка.
На этом скриншоте показан результат отбора:

Быть может, кому-то будет полезна еще одна формула –
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; АГРЕГАТ(15;6;(СТРОКА($A$2:$A$13)-СТРОКА($A$2)+1) / (ПОИСКПОЗ($A$2:$A$13;$A$2:$A$13;0)=СТРОКА($A$2:$A$13)-СТРОКА($A$2)+1); ЧСТРОК($A$2:$A2)));"")
Она работает с числами и текстом, игнорирует пустые ячейки.
Как извлечь отдельные значения с учетом регистра в Excel
При работе с данными, чувствительными к регистру, такими как пароли, имена пользователей или имена файлов, вам может потребоваться список отдельных (различных) значений с учетом заглавных и прописных букв.
Для этого используйте формулу массива, где A2: A10 - это исходный список, а B1 - это ячейка над первой ячейкой отдельного списка.
Формула массива чтобы найти уникальные значения с учетом регистра (требуется нажатие Ctrl + Shift + Enter)
{=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0; ЧАСТОТА(ЕСЛИ(СОВПАД($A$2:$A$10; ТРАНСП($B$1:B1)); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10)); ""); ПОИСКПОЗ(СТРОКА($A$2:$A$10); СТРОКА($A$2:$A$10))); 0)); "")}

Как видите, при отборе регистр здесь имеет значение.
Отбор уникальных значений по условию.
Представим, что у нас есть таблица с данными о продажах. Нам необходимо определить, какие наименования товаров заказывал определенный покупатель.
Сначала отберем из таблицы только те строки, которые удовлетворяют заданным условиям, затем из этих строк выберем уникальные наименования товаров.
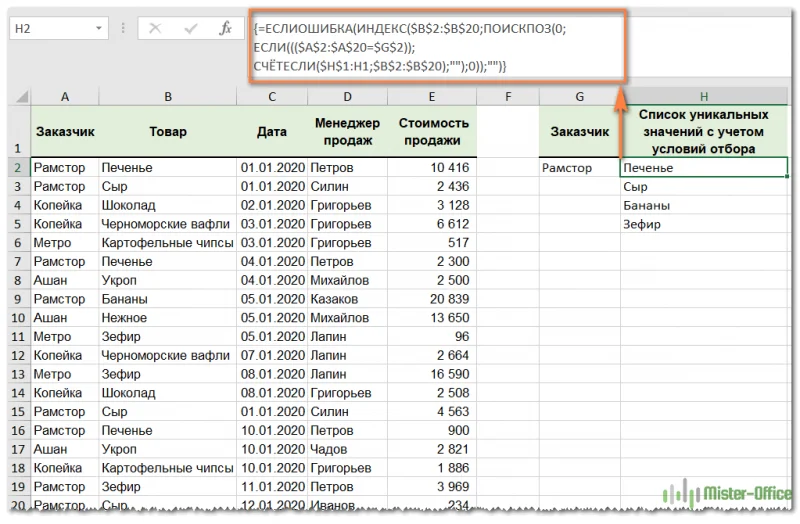
В ячейке G2 указываем нужного нам заказчика, а в H2 записываем эту формулу массива:
{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20; ПОИСКПОЗ(0;ЕСЛИ((($A$2:$A$20=$G$2)); СЧЁТЕСЛИ($H$1:H1;$B$2:$B$20);"");0));"")}
Не забудьте, что формулу массива нужно вводить в ячейку EXCEL с помощью одновременного нажатия CTRL+SHIFT+ENTER. Копируем ее по столбцу вниз при помощи маркера заполнения. Получаем список из четырех позиций.
Усложним задачу. Определим список не только для этого покупателя, но также и для определённого менеджера.
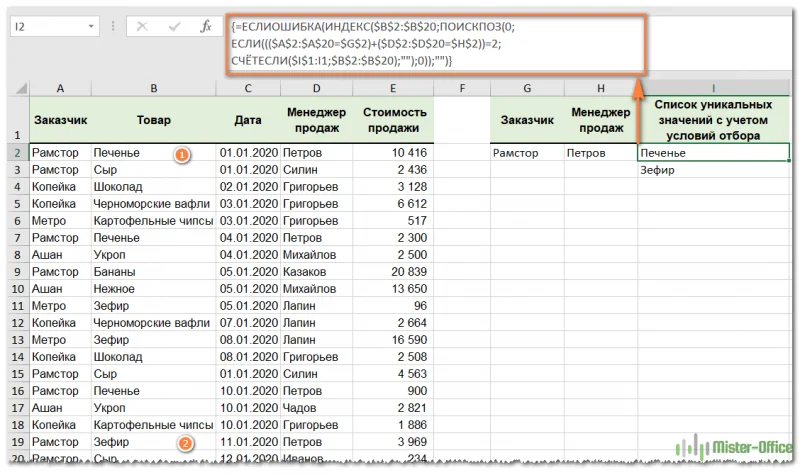
Вот наша формула массива:
{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20;ПОИСКПОЗ(0; ЕСЛИ((($A$2:$A$20=$G$2)+($D$2:$D$20=$H$2))=2; СЧЁТЕСЛИ($I$1:I1;$B$2:$B$20);"");0));"")}
Как видите, теперь товаров всего два. В подсчете принимают участие только те строки, которые удовлетворяют сразу двум условиям: должно совпасть название фирмы и фамилия менеджера. Только из них мы извлекаем уникальные названия товаров.
В случае, если условий будет больше, нужно просто добавить соответствующий критерий в функцию ЕСЛИ и изменить число 2 на 3 или большее (в зависимости от количества условий).
Более подробно о том, как извлечь нужные значения при помощи формулы ИНДЕКС ПОИСКПОЗ, читайте по ссылке: Поиск ИНДЕКС ПОИСКПОЗ по нескольким условиям.
И еще насчет товаров. Отличные предложения по серверам и прочим компьютерным комплектующим вы можете найти в комппании HP-pro.
Как найти уникальные значения в диапазоне
Формулы, которые мы описывали выше, позволяют сформировать список значений из данных определенного столбца. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных. К примеру, вы получили несколько списков товаров из различных файлов и расположили их в соседних столбцах.

Используем формулу массива
{=ДВССЫЛ(ТЕКСТ(МИН(ЕСЛИ(($A$2:$C$9<>"") * (СЧЁТЕСЛИ($E$1:E1;$A$2:$C$9)=0); СТРОКА($2:$9)*100 + СТОЛБЕЦ($A:$C);7^8));"R0C00");)&""}
Здесь A2:C9 обозначает диапазон, в котором вы хотите найти уникальные значения. E1 – это первая ячейка столбца, в который вы хотите поместить результат. $2:$9 указывает на строки, содержащие данные, которые вы хотите использовать. $A:$C указывает на столбцы, из которых вы берёте исходные данные. Пожалуйста, измените их на свои собственные.
Нажмите Shift + Ctrl + Enter , а затем перетащите маркер заполнения, чтобы вывести уникальные значения, пока не появятся пустые ячейки.
Как видите, извлекаются все уникальные и первые вхождения дубликатов.
Встроенный инструмент удаления дубликатов.
Начиная с Excel 2007 функция удаления дубликатов является стандартной. Найти ее можно на вкладке Данные > Удаление дубликатов.

Вам нужно при помощи птички указать столбцы, в которых нужно найти и удалить повторяющиеся значения. Если сделать так, как на скриншоте, то в таблице останутся только уникальные пары «Заказчик – Товар». Остальное будет удалено. Если включить только флажок «Заказчик», то останется только по одной строке для каждого заказчика и т.д.
Использование расширенного фильтра.
Если вы не хотите тратить время на выяснение загадочных поворотов формул, вы можете быстро получить список уникальных значений с помощью расширенного фильтра. Подробные инструкции приведены ниже.
- Выберите столбец данных, из которого вы хотите извлечь отдельные значения.
- Перейдите на вкладку «Данные» > группа «Сортировка и фильтр» и нажмите кнопку «Дополнительно» .
- В диалоговом окне Расширенный фильтр выберите следующие параметры:
- Установите флажок Копировать в другое место .
- В поле Исходный диапазон убедитесь, что он указан правильно.
- В параметре Поместить результат в… укажите самую верхнюю ячейку целевого диапазона. Помните, что вы можете копировать отфильтрованные данные только на текущий лист.
- Выберите пункт «Только уникальные записи».
- Наконец, нажмите кнопку ОК и проверьте результат.

Как видите, мы проверили колонку B, и затем список уникальных наименований товара, найденных в ней, поместили в столбец K.
Обратите внимание, что хотя опция расширенного фильтра называется «Только уникальные записи», она извлекает различные значения, то есть уникальные и первые вхождения повторяющихся.
Теперь немного усложним задачу.
Если требуется искать записи не по одному, а по нескольким столбцам, то можно их предварительно "склеить" при помощи функции СЦЕПИТЬ.
=СЦЕПИТЬ(A2;B2)
Записываем это в столбец F и копируем вниз. Получаем вспомогательную колонку.
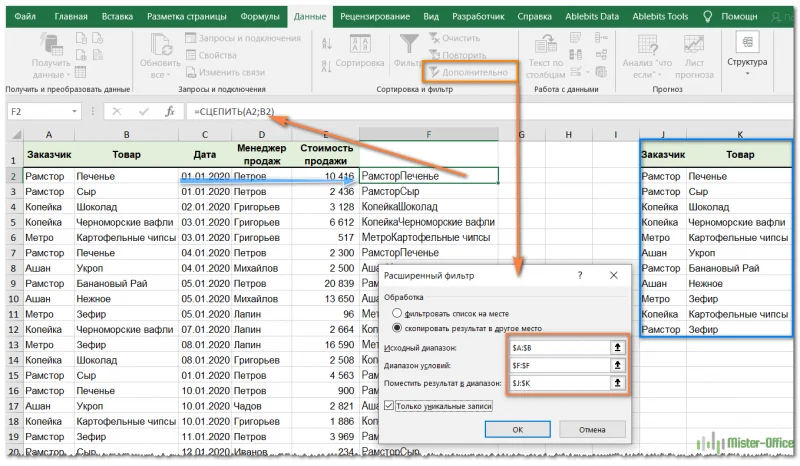
В качестве исходного диапазона мы по-прежнему выбираем данные, из которых извлекаем уникальные значения. Теперь это два столбца – A и B.
Но искать уникальные мы по-прежнему можем только в одном столбце. Вот для этого нам и пригодится вспомогательная колонка F с объединенными данными. Ее то мы и указываем в поле «Диапазон условий».
Все остальное – так же, как и в предыдущем примере.
В результате мы получили все имеющиеся в таблице комбинации «Заказчик — Товар» на основе данных во вспомогательном столбце F.
Думаю, вы понимаете, что аналогичные действия можно произвести и с тремя столбцами (например Фамилия – Имя – Отчество). Главное условие – исходный диапазон должен быть непрерывным, то есть все столбцы должны находиться рядом.
Как видите формулы здесь не нужны. Однако, если исходные данные изменятся, то все манипуляции придется повторять заново.
Извлечение уникальных значений с помощью Duplicate Remover.
В заключительной части этого руководства я покажу вам интересное решение как найти и извлечь различные и уникальные значения в таблицах Excel. Это решение сочетает в себе универсальность формул Excel и простоту расширенного фильтра. Кроме того, здесь есть несколько уникальных функций:
- Найти и извлечь уникальные или различные значения на основе записей в одном или нескольких столбцах.
- Найти, выделить и скопировать уникальные значения в любое другое место в той же или другой книге Excel.
А теперь давайте посмотрим, как работает инструмент Duplicate Remover.
Предположим, у вас есть большая таблица, созданная путем объединения данных из нескольких других таблиц. Очевидно, что она содержит много повторяющихся строк, и ваша задача состоит в том, чтобы извлечь уникальные строки, которые появляются в таблице только один раз, или различные строки, включая уникальные и первые повторяющиеся вхождения. В любом случае, с надстройкой Duplicate Remover работа выполняется за несколько шагов.
- Выберите любую ячейку в исходной таблице и нажмите кнопку DuplicateRemover на вкладке AblebitsData в группе Dedupe.
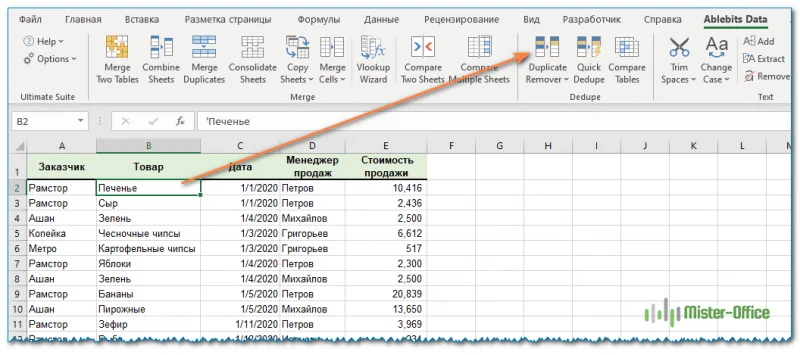
Мастер Duplicate Remover запустится и выберет всю таблицу. Итак, просто нажмите « Далее», чтобы перейти к следующему шагу.
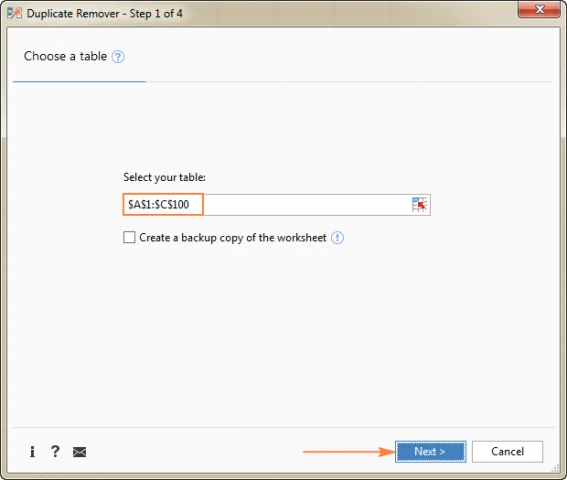
- Выберите тип значения, который вы хотите найти, и нажмите Далее :
- Уникальные
- Уникальные + 1е вхождения (различные)
В этом примере мы хотим извлечь различные строки, которые появляются в исходной таблице хотя бы один раз, поэтому мы выбираем опцию Unique + 1st occurences:

На заметку. Как вы можете видеть на приведенном выше скриншоте, есть также 2 варианта поиска дубликатов. Просто имейте это в виду, если нужно будет искать повторы в таблице.
- Выберите один или несколько столбцов для проверки уникальных значений.
В этом примере мы хотим убрать все повторяющиеся значения на основе значений в 2 столбцах ( заказчик и товар), поэтому мы выбираем только нужные нам столбцы.
В нашем случае таблица имеет заголовок, поэтому отмечаем птичкой пункт My table has headers.
Думаю, нам не нужны пустые строки, которые могут случайно встретиться при объединении данных из разных таблиц. Поэтому отмечаем такжеSkip empty cells.
Если вдруг в наших записях случайно появились лишние пробелы, то, думаю, стоит их игнорировать. Поэтому отмечаем также Ignore extra spaces.
Также наш поиск буден нечувствителен к регистру, то есть не будем при сравнении данных различать прописные и строчные буквы. Поэтому не трогаем опцию Case-sensitive match.

- Выберите действие, которое нужно выполнить с найденными значениями. Вам доступны следующие варианты:
- Выделить цветом.
- Выбрать и выделить.
- Отметить в столбце статуса.
- Копировать в другое место.
Чтобы не менять исходные данные, выберите «Копировать в другое место» (Copy to another location), а затем укажите, где именно вы хотите видеть новую таблицу – на этом же листе (выберите параметр «Custom Location» и укажите верхнюю ячейку целевого диапазона), на новом листе (New worksheet) или в новой книге (New workbook).
В этом примере давайте выберем новый лист:

- Нажмите кнопку « Готово» , и все готово!
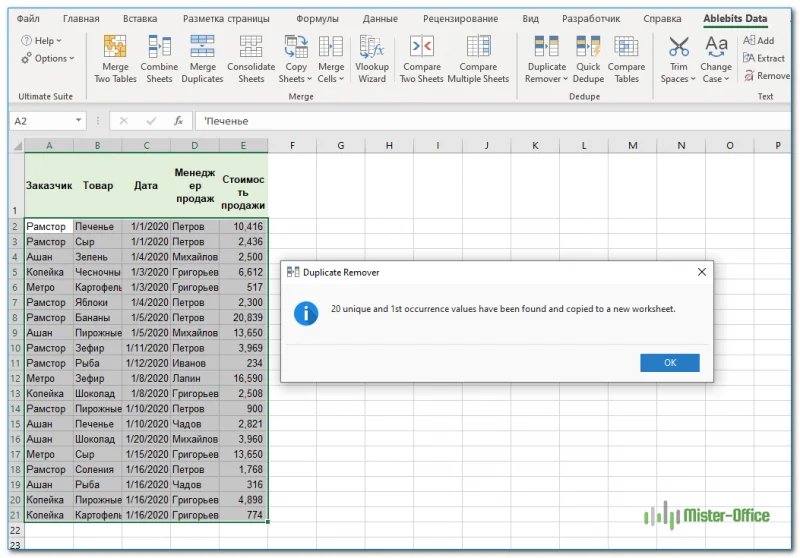
В итоге у нас осталось всего 20 записей.
Понравился этот быстрый и простой способ получить список уникальных значений или записей в Excel? Если да, то я рекомендую вам загрузить полнофункциональную ознакомительную версию Ultimate Suite и попробовать в работе Duplicate Remover.
В Ultimate Suite for Excel также включено много других полезных инструментов, которые помогут вам сэкономить много времени. Мы о них также будем подробно рассказывать в других материалах на сайте.






Здравствуйте. А как просто убрать лишь пустоты и игнорировать повторы? Перепробовал все варианты, формирует список, но повторы удаляет... мне надо просто убрать пустоты.
Я так понимаю, вы хотите убрать из списка пустые значения? Если формулой, то посмотрите здесь: Как извлечь список данных без пустот. Если речь идет о каком-то инструменте, то поясните, о каком.
ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0; ИНДЕКС(СЧЁТЕСЛИ($B$1:B1; $A$2:$A$13); 0; 0); 0)); "")
Использую данную формулу чтобы получить уникальные значения, нажимаю enter, формула записывается но поле остается пустым.Что делать не пойму, нушел файл эксель где применяется данная формула нажимаю на нее потом Энтер и опять поле становится пустым
Введите эту формулу как формулу массива (Ctrl+Shift+Enter) в ячейку В2. Затем скопируйте вниз по столбцу.
Здравствуйте. Пользовался вашей формулой
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$13; ПОИСКПОЗ(0; ИНДЕКС(СЧЁТЕСЛИ($B$1:B1; $A$2:$A$13); 0; 0); 0)); "")
но при проверке в реальных условиях понял, что не хватает различных значений.
В разных столбцах (дробь показывает что столбцы разные)
Саша / 1
Саша / А
Саша / 1
Лёха / 1У
Лёха / 2
получал результат:
Саша
Лёха
Нужный результат:
Саша
Саша
Лёха
Лёха
Добавил так:
=ЕСЛИОШИБКА(ИНДЕКС($G$3:$G$61&$E$3:$E$61;ПОИСКПОЗ(0;ИНДЕКС(СЧЁТЕСЛИ($R$2:R2;$G$3:$G$61&$E$3:$E$61);0;0);0));"")
получил:
Саша1
СашаА
Лёха1У
Лёха2
Оно вроде и есть требуемый результат, но как тогда убрать (или не выводить) в ячейке сцепленные данные (1, А, 1У, 2)
К сожалению, возможности Excel2019 ограничены. Вы можете использовать ваши результаты в столбце R как вспомогательные. Итоговые результаты можно получить при помощи формулы
=ИНДЕКС($G$2:$G$10;ПОИСКПОЗ(R3;$G$2:$G$10&$E$2:$E$10;0))
В Excel365 и выше можно использовать формулу
=УНИК(A2:B10;ЛОЖЬ;ЛОЖЬ)
Добрый день!
Помогите пожалуйста: я использую формулу из статьи: =ЕСЛИОШИБКА(ИНДЕКС(Макропараметры!$D$43:$D$145;ПОИСКПОЗ(0;ИНДЕКС(СЧЁТЕСЛИ($C$24:C24;Макропараметры!$D$43:$D$145)+(СЧЁТЕСЛИ(Макропараметры!$D$43:$D$145;Макропараметры!$D$43:$D$145)<>1);0;0); 0));"")
Эксельчик выбрал мне все значения из списка, которые являются уникальными, а те, которые повторяются вообще не взял. Но мне ведь нужно только чтобы он сформировал список без дубликатов, то есть чтобы если значения повторяются, он по разу их взял.
Подскажите пожалуйста что добавить в формулу ????
Сейчас: Надо:
Список 1 Список 2 (формирует формула): Список 3 (целевой):
Артем Артем Артем
Валера Валера Валера
Петр Павел Петр
Петр Павел
Павел
Буду очень благодарна за вашу помощь!!!
Я не совсем понял, какие значения вы хотели получить. Чтобы из списка извлечь только уникальные значения (которые повторяются - не учитываем) - используем формулу массива
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0; СЧЁТЕСЛИ($B$1:B1;$A$2:$A$10) + (СЧЁТЕСЛИ($A$2:$A$10; $A$2:$A$10)<>1); 0)); "")
в вашем примере - Артем, Валера, Павел
Чтобы извлечь значения, которые появляются хотя бы один раз
=ЕСЛИОШИБКА(ИНДЕКС($A$2:$A$10; ПОИСКПОЗ(0; СЧЁТЕСЛИ($C$1:C1; $A$2:$A$10); 0)); "")
получим список Артем, Валера, Петр, Павел
ПОдскажите, как модифицировать формулу, чтобы не выводя весь реестр уникальных значений подсчитать количество этих уникальных элементов. ПРобовал запихать СчетЗ в представленную формулу, она считает 1
используемая формула:
{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20; ПОИСКПОЗ(0;ЕСЛИ((($A$2:$A$20=$G$2)); СЧЁТЕСЛИ($H$1:H1;$B$2:$B$20);"");0));"")}
Добрый день! Думаю, здесь вы найдете ответ - Подсчет уникальных значений в Excel.
Отбор уникальных значений по условию.Отлично, уникальные значения отобраны. А как их вывести в 1 ячейку через запятую? Например: Печенье, Сыр, Бананы, Зефир? Чтобы напротив каждого поставщика вывести его заказы?
Например, имеется большой список оценок (например, за год) с фамилиями и оценками (любые, могут быть и пустыми). Как вывести уникальные значения: Петров - 2,3,4,5 (след строка) Иванов - 1,3,5 (след строка) Сидоров - 2,4. При этом желательно расставить оценки по возрастанию.
Добрый день! К сожалению, в Excel2019 и более ранних версиях вывести список уникальных значений в одной ячейке при помощи одной формулы невозможно. Если взять этот пример, то вы можете решить вашу проблему примерно такой формулой:
=ОБЪЕДИНИТЬ(", ";ИСТИНА;H2:H20)
с сортировкой —
=ОБЪЕДИНИТЬ(", ";ИСТИНА;СОРТ(H2:H20;1;1))
В Excel365 используются динамические формулы массива. Здесь ваша проблема решается одной формулой:
=ОБЪЕДИНИТЬ(", ";ИСТИНА;УНИК(ФИЛЬТР(B2:B20;A2:A20=G2;"")))
Здравствуйте. Никак не получается сделать формулу
"{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20; ПОИСКПОЗ(0;ЕСЛИ((($A$2:$A$20=$G$2)); СЧЁТЕСЛИ($H$1:H1;$B$2:$B$20);"");0));"")}"
чтобы она не учитывала одинаковые значения.
То есть, я её использую для того, чтобы сделать выгрузку из таблицы массива, соответствующего определённому наименованию.
Например, в первом столбце у меня есть разные наименования. А во втором столбце - разные суммы, которые могут повторяться:
помидор 50
свекла 70
помидор 50
морковь 50
помидор 60
В итоге нужен массив со всеми значениями для помидора следующего вида:
50
50
60
К сожалению, никак не получается скорректировать формулу. Сможете помочь?
Попробуйте эту формулу массива:
{=ЕСЛИОШИБКА(ИНДЕКС($B$2:$B$20,НАИМЕНЬШИЙ(ЕСЛИ($F$2=$A$2:$A$20,СТРОКА($A$2:$A$20)-1),СТРОКА(ДВССЫЛ("1:"&ЧСТРОК($A$2:$A$20))))),"")}
Вводить нужно сразу в диапазон.
F2 - ячейка с названием товара.
Если у вас OFFICE365, то проблема решается совсем просто:
=ФИЛЬТР($B$2:$B$20,$A$2:$A$20=F2)
Надеюсь, это поможет
Александр, большое Вам спасибо.Поменял запятые на точки с запятой и "-1" поменял на "-2" и всё отлично работает